In diesem Video stelle ich kurz UTM vor, einen kostenlosen Virtualisierer für macOS, der nicht nur simulieren, sondern auch emulieren kann.
Testweise virtualisieren wir auf einem macOS amd64 ein FreeBSD arm64.
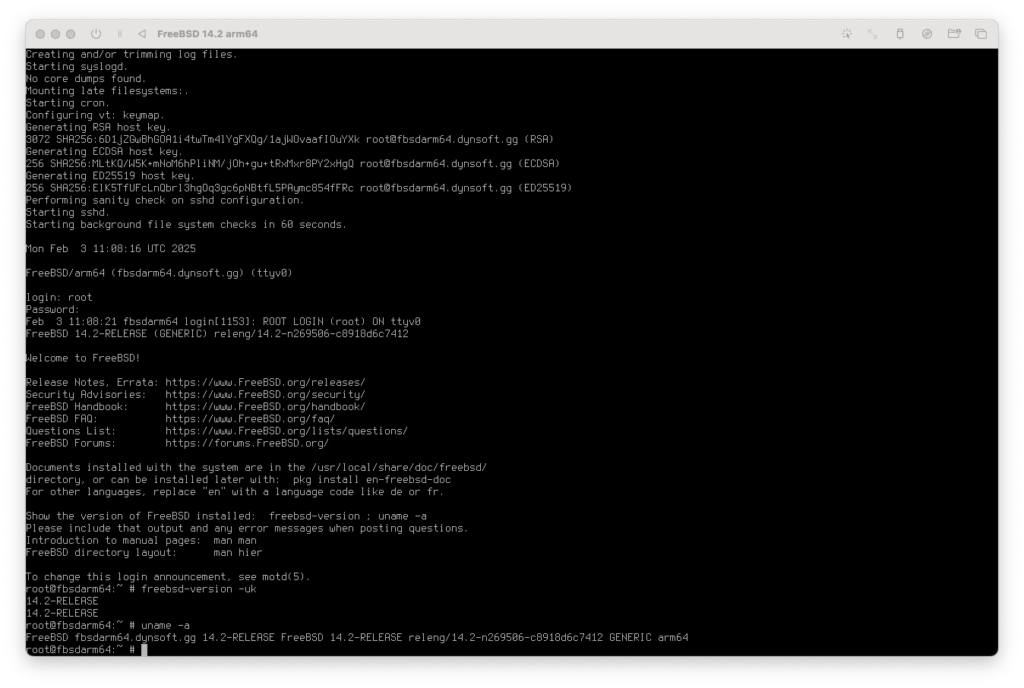
Unser installiertes FreeBSD:
In diesem Video stelle ich kurz UTM vor, einen kostenlosen Virtualisierer für macOS, der nicht nur simulieren, sondern auch emulieren kann.
Testweise virtualisieren wir auf einem macOS amd64 ein FreeBSD arm64.
Unser installiertes FreeBSD:
In diesem Video zeige ich grob, wie das Event-Handling funktioniert. Tiefer gehen wir darauf aber dann bei den einzelnen Widgets ein.
Letztlich gibt es drei Varianten, wovon die dritte „deprecated“ ist und nicht mehr in neuen Programmen benutzt werden soll:
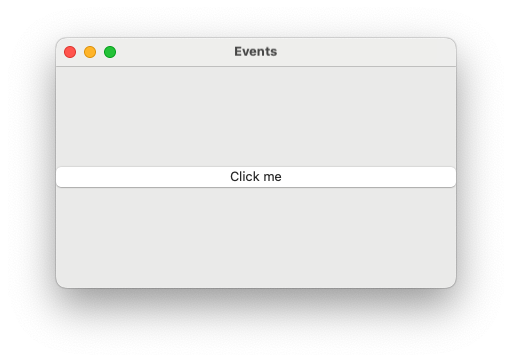
Ein Screenshot unseres Beispielprogramms.
Der Quelltext:
#include <wx/wx.h>
class MyApp : public wxApp {
public:
bool OnInit();
};
class MyFrame : public wxFrame {
public:
MyFrame();
protected:
void OnButtonClick(wxCommandEvent &event);
};
IMPLEMENT_APP(MyApp)
bool MyApp::OnInit() {
auto *myFrame = new MyFrame;
myFrame->Show();
SetTopWindow(myFrame);
return true;
}
MyFrame::MyFrame() : wxFrame(nullptr, wxID_ANY, _("Events")) {
wxButton *button = new wxButton(this, wxID_ANY, _("Click me"));
button->Bind(wxEVT_BUTTON, &MyFrame::OnButtonClick, this);
}
void MyFrame::OnButtonClick(wxCommandEvent &event) {
std::cout << "Button clicked" << std::endl;
}
In diesem Video zeige ich, wie ein wxGridBagSizer funktioniert.
Der wxGridBagSizer basiert auf dem wxFlexGridSizer, bietet aber die Möglichkeit, Widgets und Sizer darin explizit zu positionieren und der Sizer kann Zellen zusammenführen.
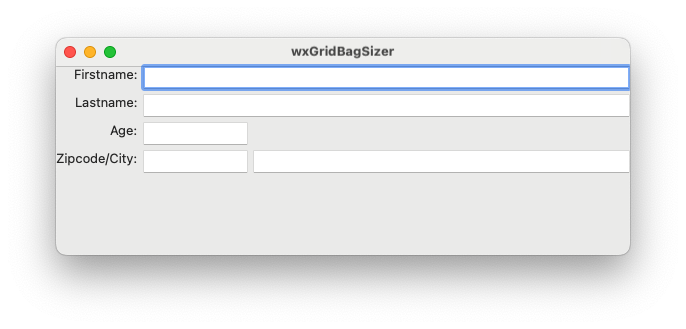
Hier ein Screenshot von unserem Beispielprogramm:
Der Quelltext:
#include <wx/wx.h>
#include <wx/gbsizer.h>
class MyApp : public wxApp {
public:
bool OnInit();
};
class MyFrame : public wxFrame {
public:
MyFrame();
};
IMPLEMENT_APP(MyApp)
bool MyApp::OnInit() {
auto *myFrame = new MyFrame;
myFrame->Show();
SetTopWindow(myFrame);
return true;
}
MyFrame::MyFrame() : wxFrame(nullptr, wxID_ANY, _("wxGridBagSizer")) {
auto *mainPanel = new wxPanel(this);
auto *gridBagSizer = new wxGridBagSizer(5, 5);
wxGBSpan twoSpan(1, 2);
gridBagSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Firstname:")), wxGBPosition(0, 0), wxDefaultSpan, wxALIGN_RIGHT);
gridBagSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), wxGBPosition(0, 1), twoSpan, wxEXPAND);
gridBagSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Lastname:")), wxGBPosition(1, 0), wxDefaultSpan, wxALIGN_RIGHT);
gridBagSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), wxGBPosition(1, 1), twoSpan, wxEXPAND);
gridBagSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Age:")), wxGBPosition(2, 0), wxDefaultSpan, wxALIGN_RIGHT);
gridBagSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), wxGBPosition(2, 1));
gridBagSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Zipcode/City:")), wxGBPosition(3, 0), wxDefaultSpan, wxALIGN_RIGHT);
gridBagSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), wxGBPosition(3, 1));
gridBagSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), wxGBPosition(3, 2), wxDefaultSpan, wxEXPAND);
gridBagSizer->AddGrowableCol(2);
mainPanel->SetSizer(gridBagSizer);
gridBagSizer->SetSizeHints(this);
}
In diesem Video zeige ich, wie einfach es ist, wxSizer zu verschachteln.
Um komplexe GUIs zu entwickeln, ist es unabdingbar, dass man Sizer ineinander verschachteln kann. Damit lassen sich einfach und übersichtlich Formulare entwickeln, die dem Benutzer einen hohen Mehrwert bringen.
Hier ein Screenshot unseres Programms:
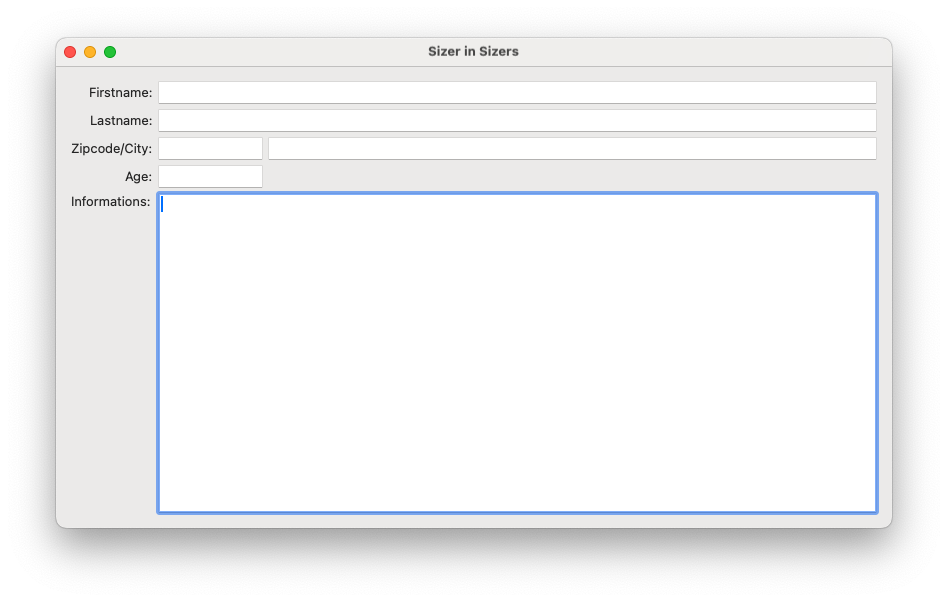
Hier der Quelltext:
#include <wx/wx.h>
class MyApp : public wxApp {
public:
bool OnInit();
};
class MyFrame : public wxFrame {
public:
MyFrame();
};
IMPLEMENT_APP(MyApp)
bool MyApp::OnInit() {
auto *myFrame = new MyFrame;
myFrame->Show();
SetTopWindow(myFrame);
return true;
}
MyFrame::MyFrame() : wxFrame(nullptr, wxID_ANY, _("Sizer in Sizers")) {
auto *mainPanel = new wxPanel(this);
auto *mainBoxSizer = new wxBoxSizer(wxHORIZONTAL);
auto *flexGridSizer = new wxFlexGridSizer(2, 5, 5);
flexGridSizer->AddGrowableCol(1);
flexGridSizer->AddGrowableRow(4);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Firstname:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Lastname:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Zipcode/City:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
auto *addressSizer = new wxBoxSizer(wxHORIZONTAL);
addressSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY));
addressSizer->AddSpacer(5);
addressSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 1);
flexGridSizer->Add(addressSizer, 0, wxEXPAND);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Age:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY));
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Informations:")));
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
mainBoxSizer->Add(flexGridSizer, 1, wxEXPAND | wxALL, 15);
mainPanel->SetSizer(mainBoxSizer);
mainBoxSizer->SetSizeHints(this);
}
In diesem Video zeige ich die Verwendung von wxFlexGridSizer.
Im Gegensatz zum wxBoxSizer, der Elemente nur horizontal oder vertikal ausrichten kann, dient der wxFlexGridSizer wie eine Tabelle, in der bestimmt werden kann, welche Spalten und Zeilen sich ausdehen durfen und in dem man einfach Formulare zusammensetzen kann.
Hier ein Screenshot unseres Programms:
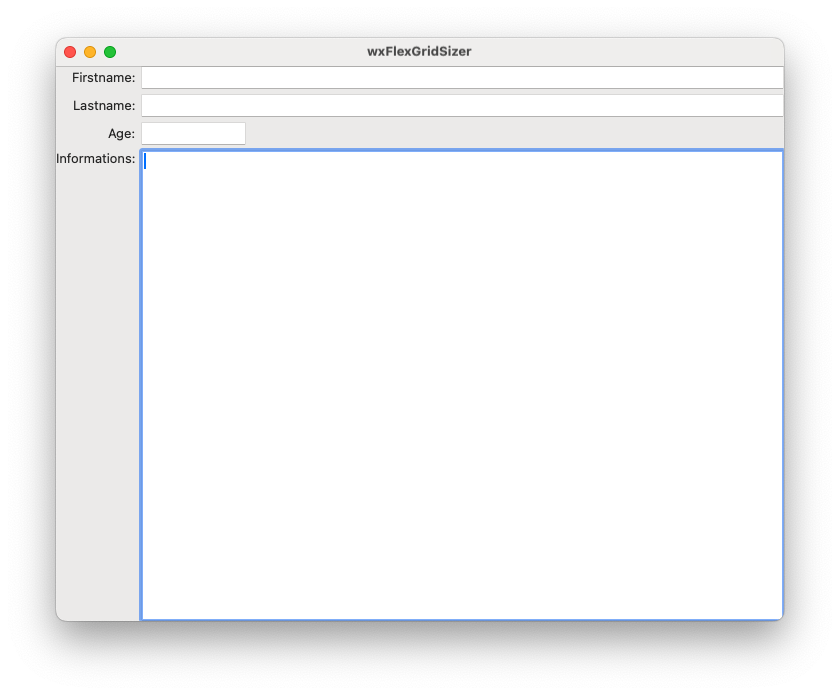
Hier der Quelltext:
#include <wx/wx.h>
class MyApp : public wxApp {
public:
bool OnInit();
};
class MyFrame : public wxFrame {
public:
MyFrame();
};
IMPLEMENT_APP(MyApp)
bool MyApp::OnInit() {
auto *myFrame = new MyFrame;
myFrame->Show();
SetTopWindow(myFrame);
return true;
}
MyFrame::MyFrame() : wxFrame(nullptr, wxID_ANY, _("wxFlexGridSizer")) {
auto *mainPanel = new wxPanel(this);
auto *flexGridSizer = new wxFlexGridSizer(2, 5, 5);
flexGridSizer->AddGrowableCol(1);
flexGridSizer->AddGrowableRow(3);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Firstname:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Lastname:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Age:")), 0, wxALIGN_CENTER_VERTICAL | wxALIGN_RIGHT);
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY));
flexGridSizer->Add(new wxStaticText(mainPanel, wxID_ANY, _("Informations:")));
flexGridSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY), 0, wxEXPAND);
mainPanel->SetSizer(flexGridSizer);
flexGridSizer->SetSizeHints(this);
}
In diesem Video beginnen wir mit Sizern, im Speziellen mit wxBoxSizer.
Layoutmanager sind essentiell bei der Programmierung von grafischen Benutzeroberflächen. Gab es zu Beginn der grafischen Benutzeroberflächen teils nur die Möglichkeit, Elemente absolut positioniert zu platzieren, bieten Layoutmanager, bei wxWidgets Sizer genannt, die Möglichkeit, die Ausrichtung und Anordnung dynamisch zu gestalten.
Der wxBoxSizer kann Elemente horizontal oder vertikal anordnen, proportional vergrößern und verkleiner, ausrichten und vieles mehr.
Hier ein Screenshot unseres Programms:
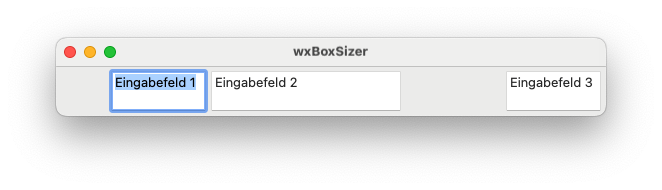
Hier der Quelltext:
#include <wx/wx.h>
class MyApp : public wxApp {
public:
bool OnInit();
};
class MyFrame : public wxFrame {
public:
MyFrame();
};
IMPLEMENT_APP(MyApp)
bool MyApp::OnInit() {
auto *myFrame = new MyFrame;
myFrame->Show();
SetTopWindow(myFrame);
return true;
}
MyFrame::MyFrame() : wxFrame(nullptr, wxID_ANY, _("wxBoxSizer")) {
auto *mainPanel = new wxPanel(this);
auto *mainBoxSizer = new wxBoxSizer(wxHORIZONTAL); // wxVERTICAL
mainBoxSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY, _("Eingabefeld 1")), 1, wxEXPAND | wxLEFT | wxTOP | wxBOTTOM, 5);
mainBoxSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY, _("Eingabefeld 2")), 2, wxEXPAND | wxALL, 5);
mainBoxSizer->AddStretchSpacer();
mainBoxSizer->Add(new wxTextCtrl(mainPanel, wxID_ANY, _("Eingabefeld 3")), 1, wxEXPAND | wxRIGHT | wxTOP | wxBOTTOM, 5);
auto *tmp = new wxTextCtrl(mainPanel, wxID_ANY, _("Eingabefeld 0"));
mainBoxSizer->Insert(0, tmp, 1, wxEXPAND | wxRIGHT | wxTOP | wxBOTTOM, 5);
mainBoxSizer->InsertSpacer(0, 50);
mainBoxSizer->Detach(1);
tmp->Destroy();
mainPanel->SetSizer(mainBoxSizer);
mainBoxSizer->SetSizeHints(this);
std::cout << "Element count: " << mainBoxSizer->GetItemCount() << std::endl;
std::cout << "Position: " << mainBoxSizer->GetPosition().x << "x" << mainBoxSizer->GetPosition().y << std::endl;
std::cout << "Size: " << mainBoxSizer->GetSize().GetWidth() << "x" << mainBoxSizer->GetSize().GetHeight() << std::endl;
}
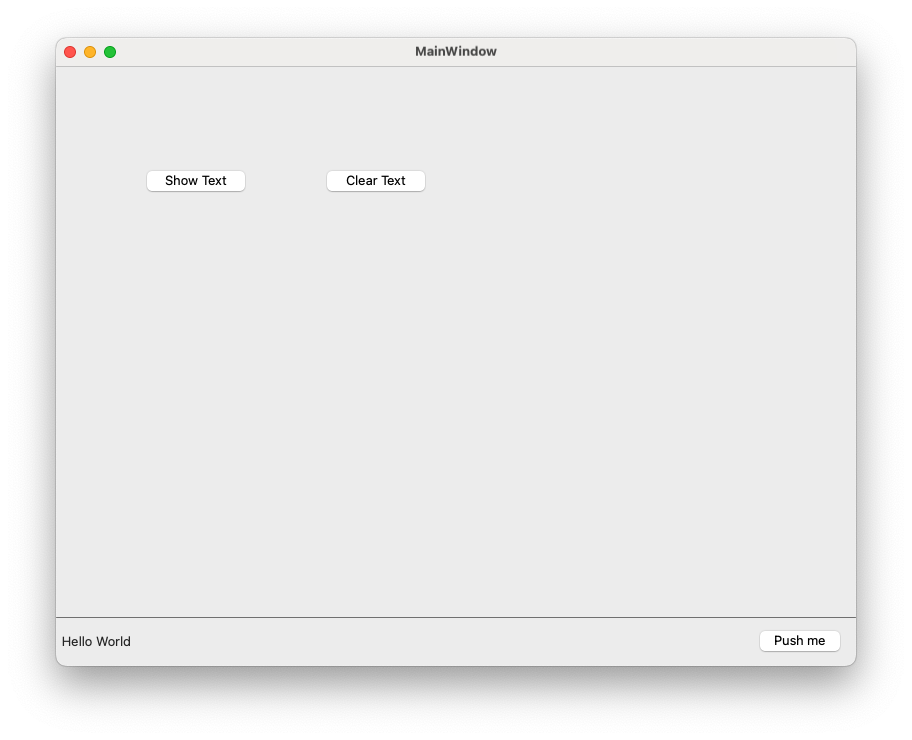
In diesem Video zeige ich, wie man mit der Statusbar (QStatusBar) umgehen kann.
Viele Fenster des benutzten Fenstermanagers haben am unteren Rand eine Leiste, die manchmal einfach nur da ist, manchmal Informationen anzeigt, manchmal aber auch Interaktionen anbietet. Dieses Video zeigt, wie man Informationen dauerhaft oder für eine gewisse Zeit anzeigt oder Widgets hinzufügt.
Hier ein Bild unseres Programms:
Ich gebe es zu: Ich habe meinen Server, der online steht und, unter anderem, dieses Blog betreibt, ziemlich und auch lange vernachlässigt. Installiert war ein FreeBSD 13.3 amd64. Die aktuelle Version aus der 13er-Reihe war 13.4. So weit zurück war ich nicht, was aber das größere Problem war, waren die installierten Packages, allen voran PostgreSQL, MySQL und PHP.

Ich dachte mir, ich ziehe mein FreeBSD 13.3 direkt auf 14.2, damit zumindest das Grundsystem mal aktuell ist und Dienste wie SSH und ähnliche mit Sicherheitsupdates versorgt werden. Die Packages wollte ich dann irgendwann später nachziehen.
Also begann ich, das Upgrade durchzuführen. Das lief auch gut, bis zum ersten Reboot. Der Server kam nicht mehr hoch. Zumindest dachte ich das. Von Hetzner ließ ich mir eine KVM anschließen und war doch erstaunt: Der Server ist hochgefahren und der erste Schritt des Upgrades war erfolgreich. Jedoch hatte der Server kein Netzwerk mehr. Warum, weiß ich nicht, ich konnte es aber schnell lösen, indem ich von meiner statischen Netzwerkonfiguration auf DHCP umgestellt habe. Also weiter mit dem Upgrade.
Der zweite Reboot ging dann leider in die Hose. Ich habe mir wieder eine KVM von Hetzner anschließen lassen (die erste hatte ich nur für eine Stunde geliehen) und sah, dass ich beim Mergen der Konfigurationen irgendwo zwei Zeilen „wegoptmiert“ hatte und so ein Script, welches zum Booten benötigt wird, fehlschlug. Reboot. Die Maschine kam hoch, schmiss aber ein paar Fehlermeldungen. Problematisch war, dass ich mich mit keinem meiner Accounts anmelden konnte. Irgendwelche anderen Scripte waren auch kaputt.
Anscheinend habe ich es entweder geschafft, ein paar Dinge kaputt zu machen (was mir zuvor noch nie passiert war), oder es gab irgendwelche anderen Probleme. Durch den Boot in den Single-User-Mode konnte ich mich umsehen und habe versucht, die Probleme zu fixen. Vergeblich. Dann hatte ich aber auch keine Lust mehr und die KVM war ja auch nur für drei Stunden geliehen, es musste eine Lösung her. Fakt war, dass im etc-Verzeichnis einiges kaputt war.
Also kopierte ich das etc-Verzeichnis von einer funktionsfähigen Installation von FreeBSD 14.2, schob meine Konfigurationen hinein und kopierte alles per „scp“ auf meinen Server. Zumindest das Grundsystem funktionierte dann wieder und ich brauchte die KVM nicht mehr.
Doch kaum ein Dienst funktionierte. Wir (meine Familie und ich) sind allerdings auf ein paar Dienste angewiesen: Mail, Card– und CalDav, mein Blog, NextCloud, meine Projekte, Git, usw.
Es blieb mir nichts übrig, als alles hochzuziehen. Wieder einmal dachte ich mir, wie sinnvoll es wäre, verschiedene Dienste in verschiedenen Jails zu organisieren und regelmäßiger Updates und Upgrades durchzuführen. Es war gut ein Tag Arbeit, alles wieder ans Rennen zu bekommen, zumal auch Packages wegfielen (wxWidgets 2.8, welches ich für compow.de benötige).
https://youtu.be/o7JoKRrQDkQIch möchte bald ein paar Videos machen, für die wir ein DMBS benötigen. In diesem Video zeige ich, wie man eine einfache (unsichere und für Produktivumgebungen nicht zu verwendende!) MySQL-Datenbank unter FreeBSD (14.2) installieren kann.
Ich möchte bald ein paar Videos machen, für die wir ein DMBS benötigen. In diesem Video zeige ich, wie man eine einfache (unsichere und für Produktivumgebungen nicht zu verwendende!) PostgreSQL-Datenbank (17) unter FreeBSD (14.2) installieren kann.